Champion in T-footprint International Maker Competition
During the period from August 13th to August 15th, 2021, Dell EMC Technology Group, a well-known cloud computing and big data information management technology leader in the world’s top 500, held an international creative competition around Pravega, At one time, 23 participating teams gathered, including the BAT Dachang Cloud team, which is a master of the cloud.
Under the leadership of the team leader Fly Yu, all members of the team are full of creative wisdom, actively participate, crazy coding and sleepless nights of joint adjustment, determined to win. The final result is also gratifying. The T-footprint team stood out from the 23 participating teams and won the first place in the maker competition with the achievement of “chip software CI/CD big data analysis and status monitoring”.

We all know that CI (Continuous Integration)/CD (Continues Deployment) plays a very important role in the software development/iteration process, and the same is true in the embedded world.
With the rapid development of technologies such as the Internet of Things, intelligent driving, machine learning, and 5G, the requirements for embedded systems, especially software, are getting higher and higher. consumption and storage limitations; on the other hand, there are stricter standards for software accuracy, security, and stability.
In the actual project, our embedded SDK (Software Development Kit) is faced with more and more types of hardware that need to be adapted, and the complexity is getting higher and higher, from ARM Cortex-M0/M4/M7/CM33, Up to 60 types of hardware from ARM-Cortex A series and various architectures including DSC/DSP. In addition, a complete SDK not only needs to provide basic BSP and driver layer support, but also needs to integrate third-party middleware to facilitate secondary development for customers. For example, it supports mainstream RTOS, graphics and image processing, machine learning, audio processing, motor control and other popular fields.
Such a complex SDK brings great challenges to the control of software quality. There are many combinations of test points, complex test branches, many test items, and huge test results and log data. It often requires a lot of manpower and time to analyze manually, so that the test results are difficult to summarize and the overall software quality is difficult to control, especially It is difficult to obtain the support of real data, and it is difficult to obtain useful information from historical data. Such CI/CD has seriously hindered the development and iteration of SDK.
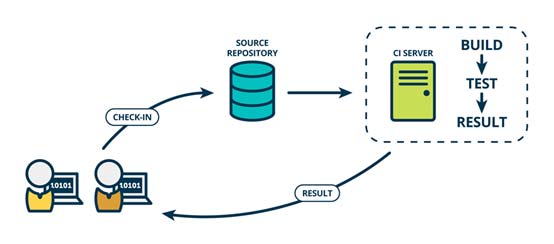
One of the pain points of CI/CD is the huge number of test log analysis, manual analysis is slow and time-consuming. Embedded software logs usually do not have a fixed format, mainly including: software compilation logs, firmware download logs, and test execution logs. The purpose of log analysis is to find the most valuable information in the log, and to quickly classify and locate problems through classification, so as to help developers quickly fix problems.
The second pain point of CI/CD is that software quality/status cannot be effectively monitored. Software development is a very uncertain process. Changes in requirements, structure adjustments, and personnel changes may bring great risks to software quality. Therefore, it is very important to control the entire software development process, which requires the support of real data, and needs to understand various details of the current iterative version, so as to control the overall situation and reduce software quality risks.
Based on the above analysis, what we urgently need to solve is the status and result analysis of SDK CI. Apache Flink is the current mainstream data analysis engine, and Pravega is a very good streaming storage engine that supports the definition of various data processing methods. With Flink, it can meet the real-time complex data processing requirements of various data, and can provide Good real-time and consistency.
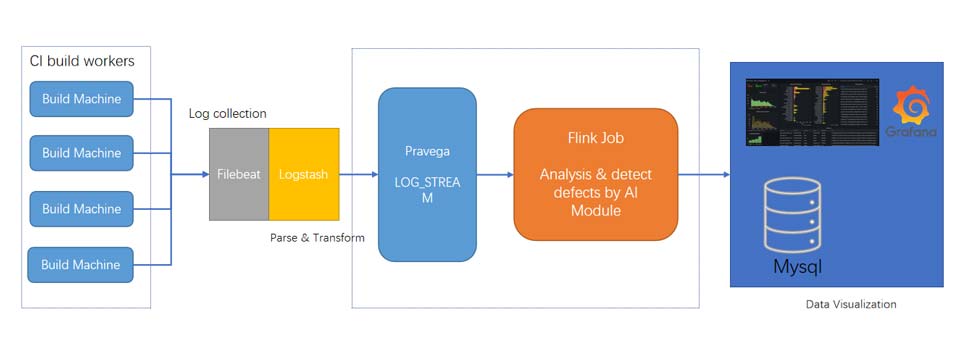
The image above is the architecture of this project. The streaming log data generated by CI belongs to streaming data. After simple cleaning of the data by filebeat + logstash, it is continuously written to the Pravega stream. Pravega supports data persistence and provides elastic and infinite scalability. Therefore, Pravega is very suitable for log data. Not only does it eliminate the need for additional storage, but Pravega can also buffer the data to achieve the effect of cutting peaks and filling valleys. The introduction of Pravega greatly simplifies the system architecture and improves the concurrency capability of the system.
In the data processing part, a model based on Naive Bayes algorithm is used. The Naive Bayes algorithm is simple and effective, and is often used in text classification, such as spam detection. In our model, keywords and phrases are selected as feature values, and after a large number of historical log training, the accuracy rate can basically reach more than 95%.
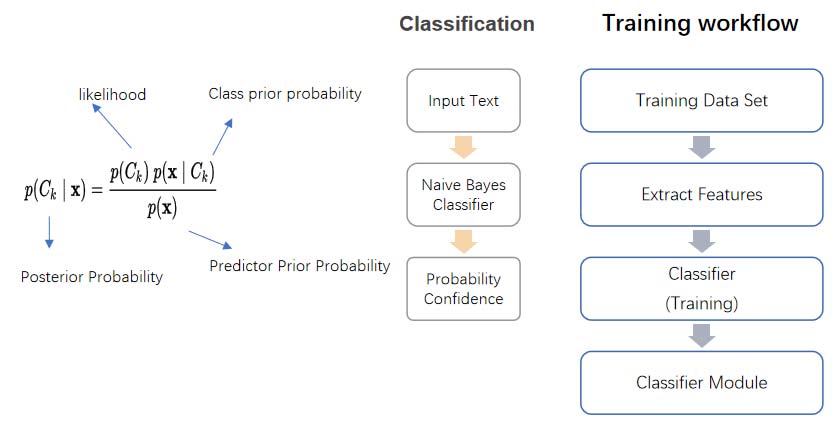
In the Flink job part, the above model is embedded in the form of UDF, and Pravega Stream acts as the data source. The characteristics of Pravega determine that events will not be missed, repeated, or processed out of order. If configured properly, Flink jobs can also automatically recover from where they left off.
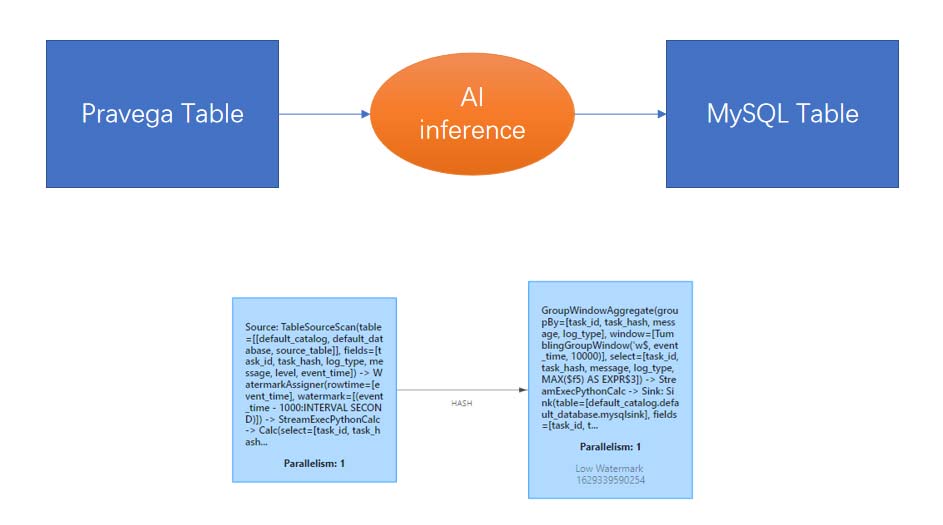
Pravega provides a great and easy-to-use flink-connector, the processed data is written to the business database MySQL storage, and finally a dynamic, real-time visual report is perfectly presented through Grafana.
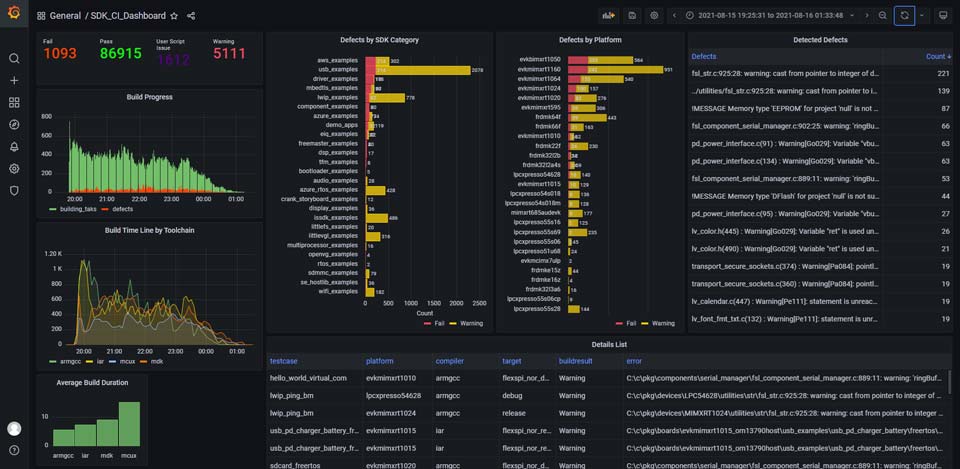
Real-time visual status monitoring report, support viewing status at any historical time point. The report provides a summary of the results of the overall software test, analysis of the compilation speed of each compiler, the test progress of the hardware platform, and the prediction and classification of specific test failure reasons. At the same time, through the further integration of pravega, the CI system can use pravega to realize real-time log on the web side. The server backend reads data from the stream and sends it to the browser front end through websocket, which solves the huge defect of log loss in the old design. The complexity of the data processing end system is simplified.
After the solution in this article is implemented, it has largely solved the pain points of SDK CI, the software development iteration efficiency has been greatly improved, and the entire development and testing cost; and the data has been used to improve the SDK development process and the CI system. The optimization provides a reliable basis.
In short, the value of this project is reflected in the following aspects:
1. Real-time streaming data analysis and real-time visualization system are realized, which supports unified analysis and processing of historical data and real-time data. Building a real-time data analysis platform itself is extremely complicated. Fortunately, the architecture based on Pravega and Apache Flink simplifies the system complexity, including but not limited to the collection, transformation, aggregation, verification, analysis, storage, and visualization of real-time data. And so on various data scenarios.
2. The project is easy to implement. Like Apache Flink, Pravega has a rich surrounding ecology, providing various plug-ins and clients in multiple languages; and Pravega and Flink also have the characteristics of high availability and easy expansion. In the actual implementation process, it can be carried out according to the actual situation. Adaptation; Since Pravega has taken cloud application scenarios into consideration at the beginning of its design, it is easy to use container orchestration. This project is all based on docker development. The whole process is very convenient for development, testing and deployment, which greatly simplifies the landing cost.
3. AI based on Bayesian algorithm can clean and screen original irregular logs in real time, which solves the difficulty of how to screen log analysis. The Naive Bayes algorithm is simple and efficient, especially suitable for text and log classification. Appropriate feature selection can quickly adapt to the analysis or classification of various logs, with high accuracy and easy implementation.
Returning to our award-winning “event”, the success of the Maker Contest not only showed the outside world the technical strength and outstanding performance of our Thinking team in the field of chip R&D automation testing and big data analysis and processing, but also this surprise The “big event” deserves all the “thinkers” to celebrate.
This competition is full of difficulties for “Thinkers”, but also challenges. In order to surpass the competitors, the team members are sweating in their hearts, but at the same time, there is a fire in each member’s heart, not to be outdone. In the end, they defeated them through superb technology and wisdom.
Finally, the Master said, “Everyone has ideas, and the one who stands out the most will have the greatest success”! I also hope that this competition can give you confidence and encouragement. If you have a dream you want to dream, you may as well go for it with confidence. I wish you all your own success!

Official WeChat account of T-footprint was born
2022-04-22
On October 9, 2021, the official WeChat account of Siji Information “Siji Information” issued the first tweet “Siji Report” and officially put it into use.

Focus on CICV2021| | Car Gauge Chip to Meet the New Challenge
2022-04-22
From May 25th to 27th, 2021, the 8th International Intelligent Connected Vehicle Technology Annual Conference (CICV 2021) hosted by the China Society of Automotive Engineers will be held in Beijing.

A sunny day, A place where hope rises
2022-04-22
In a Hope Primary School in Suqian, Jiangsu, the five-star red flag is rising. “The red sun is rising, and its path is bright.” On this day, the sun is shining…